
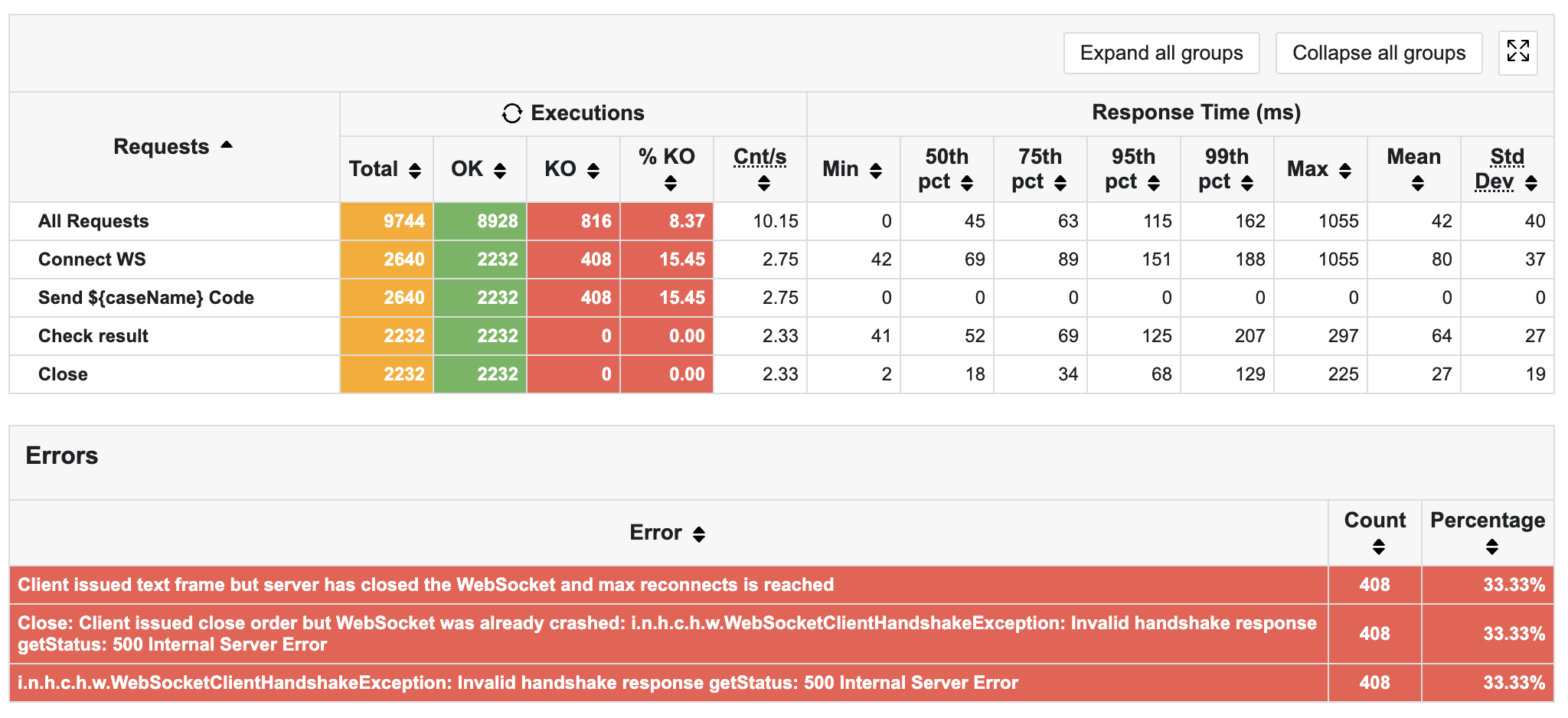
[Performance] 비동기 콜백 기반 Max Latency 41.5% 개선 (4-way handshake 병목 해소)
들어가기 전에 앞서, 해당 부분은 제 지식과 참고 자료를 활용하여 정리한 것이므로 틀린 부분이 있을 수도 있다는 말씀을 드립니다.
🫧 문제 상황
저번 글에서는 Multi-Puller를 도입하여 Max Latency를 75.7% 낮춘 경험을 작성하였다.
그런데 해당 글에서도 썼다시피 결과를 보니 close() 시 Max Latency가 207ms -> 296ms로 약 43% 증가하는 것을 발견하였다.
단순히 우연의 일치인가 싶어 이후 테스트를 몇 번 더 수행했었는데, 그때마다 Max Latency가 약 300ms 정도를 웃도는 것을 확인하였다.
아래 이미지는 실제 Poller를 하나 더 도입하며 생긴 latency 수치이다.
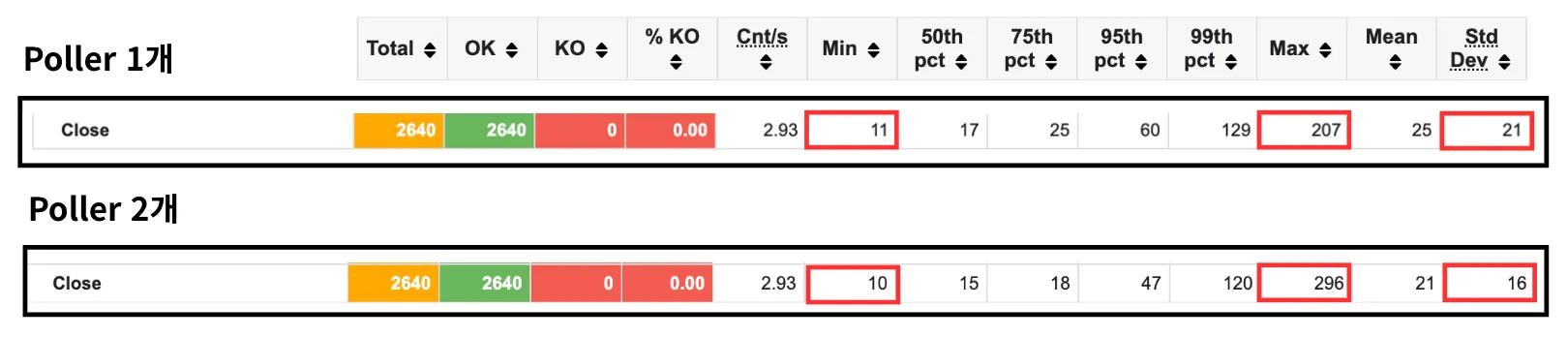
p95: 60ms → 47ms 감소max: 207ms → 296ms 증가표준편차: 21 → 16으로 감소
해당 부분을 보면 모든 결과는 좋아졌지만 max Latency만 훅 튀고 있음을 알 수 있다.
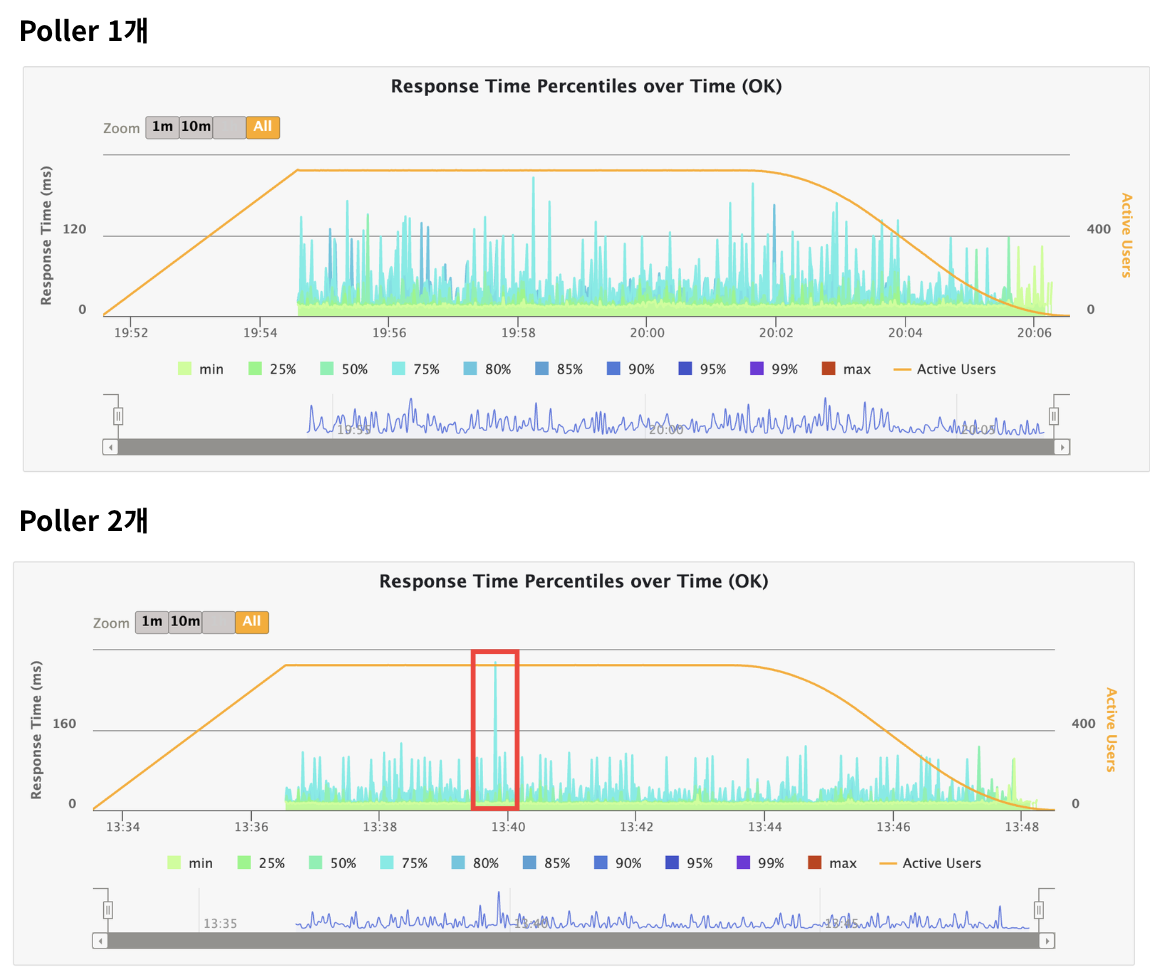
전에 발생했던 문제 또한 지연으로 인해 Max Latency가 두드러지는 현상이 나타났던 것이었으므로, 이번에도 어딘가 지연이 발생했을 것이라 추측할 수 있었다.
그래서 close() 과정을 추적하며, 어떤 부분에서 문제가 발생할 수 있는지를 파악하고 문제에 대한 원인을 찾고자 한다.
이를 Prometheus/Grafana를 활용하여 증명하고자 한다.
+) 문제 해결 과정에서, 지표의 한계를 느껴 핀포인트로 추적 과정을 담고자 했으나 웹소켓 지원 미흡, latency 오버헤드 발생의 이유로 열심히 연결했던 핀포인트를 제거했다…
🫧 close() 과정
그렇다면 close()를 호출하면 내부적으로 어떤 일이 발생하는지 보자.
내부적으로 close()는 다음과 같이 동작한다.
- 클라이언트의 close() 호출
- 클라이언트와 백엔드가 Close Frame을 주고 받음
- 클라이언트 -> 백엔드로 FIN 패킷 전송
- 이때 FIN은 4-way handshake 과정 중 하나이다.
- 클라이언트 -> 백엔드로 FIN 전송
- 백엔드 -> 클라이언트로 잘 받았다는 ACK 응답을 다시 전송
- 송신 버퍼(Recv-Q)에 내용이 남았다면 마저 쓰기
- 백엔드 -> 클라이언트로 FIN 전송
- 클라이언트 -> 백엔드로 ACK 전송
- FIN 패킷 -> 소켓 이벤트 변경 -> Poller 확인 후 스레드 할당
- 할당된 스레드가 read() 시 -1 상태 감지
- Selector의 cancelledKey Set에 추가
- 이후 cancelledKey Set은 Poller가 다음 루프에서 select()/selectNow() 호출 시 정리
- 스레드의 객체 정리
이때 4-way handshake, Poller의 cancelledKey Set 정리, 스레드의 객체 정리는 동시다발적으로 처리될 수 있다.
우선 기본적으로 서버가 어떤 변화가 있었는지 파악하도록 하자.
✨ 가설 1: Poller의 빠른 처리로 인해 객체가 전보다 빠르게 생성될 것이다. (참)
Poller -> Selector 처리 과정에서 Selector가 전보다 더 빠르게 객체를 생성할 것이라 예측하였다.
실제로 allocated의 경우 메모리 할당의 변동폭이 컸다.
여기서 allocated는 현재까지의 총 메모리 할당량을 뜻한다.
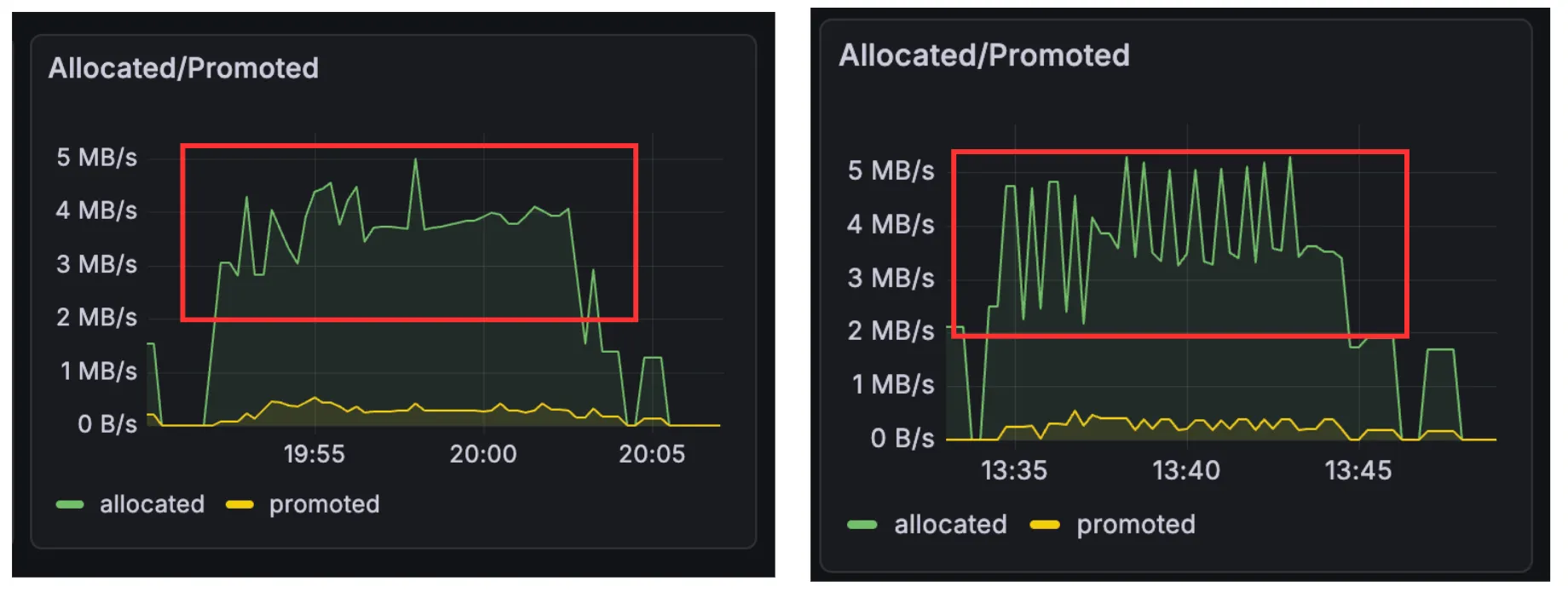
총 할당량 계산 결과, Poller 1개의 경우 163.74MB, 2개의 경우 171.30MB로 거의 비슷한 수치를 내고 있음을 알 수 있다.
그러나 삐죽삐죽 메모리가 치솟고 있음을 알 수 있는데, 이는 메모리가 몰아서 한 번에 할당되고 있음을 나타낸다.
따라서 Multi-Poller 도입으로 인해 처리가 지연되던 요청들이 한 번에 처리되며 객체가 빠른 시간에 생성되고 있음을 확인하였다.
✨ 가설 2: GC 수행이 앞당겨질 것이다. (+ STW 시간이 증가할 것이다.) (거짓)
가설을 세운 흐름은 다음과 같다.
Poller 두 개로 SocketChannel (Acceptor이 만드는 웹소켓용 객체)이 엄청 빠르게 만들어짐 -> GC가 전보다 더 빠르게 일어날 것.
실제로 WS 연결 속도가 p99 기준 23.1% 감소하였으므로 객체의 생성 속도가 전보다 앞당겨질 것으로 예측하였다.
그러나 테스트 결과, GC 수행 시간은 비슷했다.
테스트 시작 후 약 3분 만에 GC가 발생하는 사실 또한 비슷했으며, STW 시간도 비슷하여 객체에서 발생하는 문제가 아님을 짐작할 수 있었다.
(그런데 당연한 소리였다. API 호출양은 변화하지 않았으므로 객체의 양은 달라지지 않는다..)
✨ 가설 3: 객체의 생명 주기가 길어졌을 것이다. (참)
그러면 객체가 빨리 만들어지는데 왜 GC가 빠르게 발생하지 않는지에 대한 의문이 들었다.
따라서 객체의 살아남는 시간이 길어졌을 것이라 추측하였다.
모니터링 지표 확인 결과, Young -> Survivor 영역으로 이동하는 객체가 많아졌다는 것을 확인할 수 있었다.
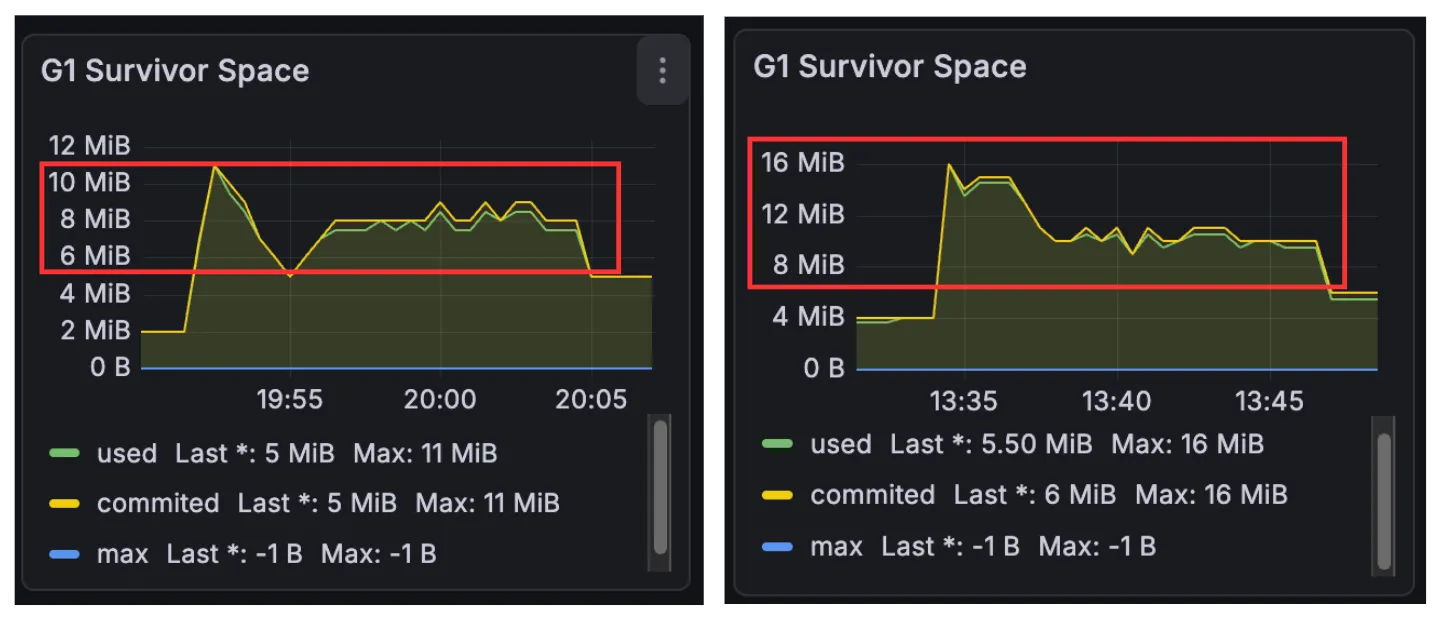
그러나 Survivor -> Old 영역의 이동은 잘 일어나지 않았음을 확인할 수 있었는데, Old 영역으로 이동하기 전 객체 정리로 인해 발생한 문제로 추측할 수 있었다.
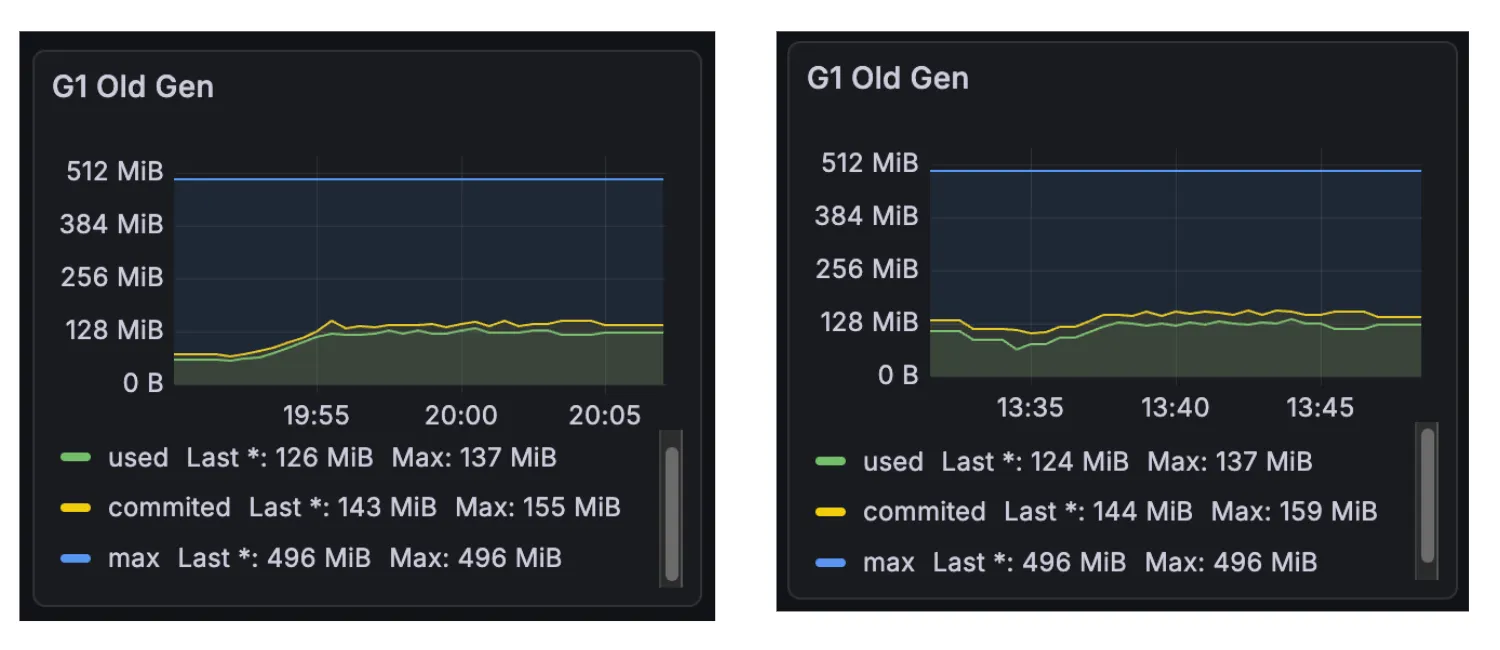
가설 1에서 객체 생성 주기가 몰아서 할당됨을 확인하였으므로 예상보다 GC가 빠르게 호출되어 Survivor 영역으로 이동하는 객체가 많아졌음을 파악할 수 있었다.
그러나 가설 2에서 GC 수행 시간이 비슷했다는 결과가 나왔다. 가설 1과 3을 미루어 볼 때, 이는 객체의 생성 주기가 엄청나게 빨라지지 않아 GC 모니터링 시 잘 드러나지 않을 것으로 생각하였다.
이를 바탕으로 지연 원인을 파악해보자.
✨ 가설 4: FD 반환 시 지연이 발생할 것이다. (거짓)
실제 Process Open File 확인 시 기울기가 유사하게 나왔으므로 해당 가설은 거짓임을 확인할 수 있었다.
✨ 가설 5: write() 시 지연이 발생할 것이다. (거짓)
코드 실행 API 특성상 요청 시에는 input을 읽고, 응답 시에는 output을 내 줘야 한다.
따라서, 버퍼에 쓰는 과정에서 추가적인 지연이 발생할 것으로 예측했다.
그러나 버퍼 사용률과는 유의미한 상관 관계를 내지 못하였다.
✨ 가설 6: Poller 상태 업데이트 시 공유 Selector 접근 과정에서 지연이 발생할 것이다. (거짓)
실제로 정리할 패킷의 FD 리스트를 Selector이 가지고 있다가, 한 번에 Poller를 깨우면서 이를 정리하게 된다.
그러나 Poller를 두 개로 늘리면서, Selector이 처리해야 할 양이 많아졌고, 이 부분에서 지연이 발생할 것으로 예측하였다.
그러나 실제로 Poller를 새로 만들지 않고, Tomcat의 pollerThreadCount를 2로 늘렸는데, 이는 Selector를 개별적으로 가지도록 프로그래밍되어 있다고 한다.
따라서 공유 Selector는 성립하지 않는다. (오히려 락 부분을 의심 해야 한다.)
✨ 가설 7: 로그 부분에서 지연이 발생할 것이다. (거짓)
나의 프로젝트를 보면 사진처럼 Slf4j를 활용하여 로그를 남기고 있다.
이 부분은 테스트 시 제대로 소켓 연결이 이루어졌나 찍어보기 위함인데, 실제 테스트 상황에서 log.info까지 모두 찍어놓도록 구현한 것이었다.

실제로 Slf4j의 경우 따로 건드린 것이 없다면 스프링 기본 설정인 LogBack를 활용하는데, 이에 대해 버퍼에 쓰는 과정에서 세션 정리와 겹쳐 혹시 지연이 발생할 수도 있지 않을까 하는 생각이 들었다.
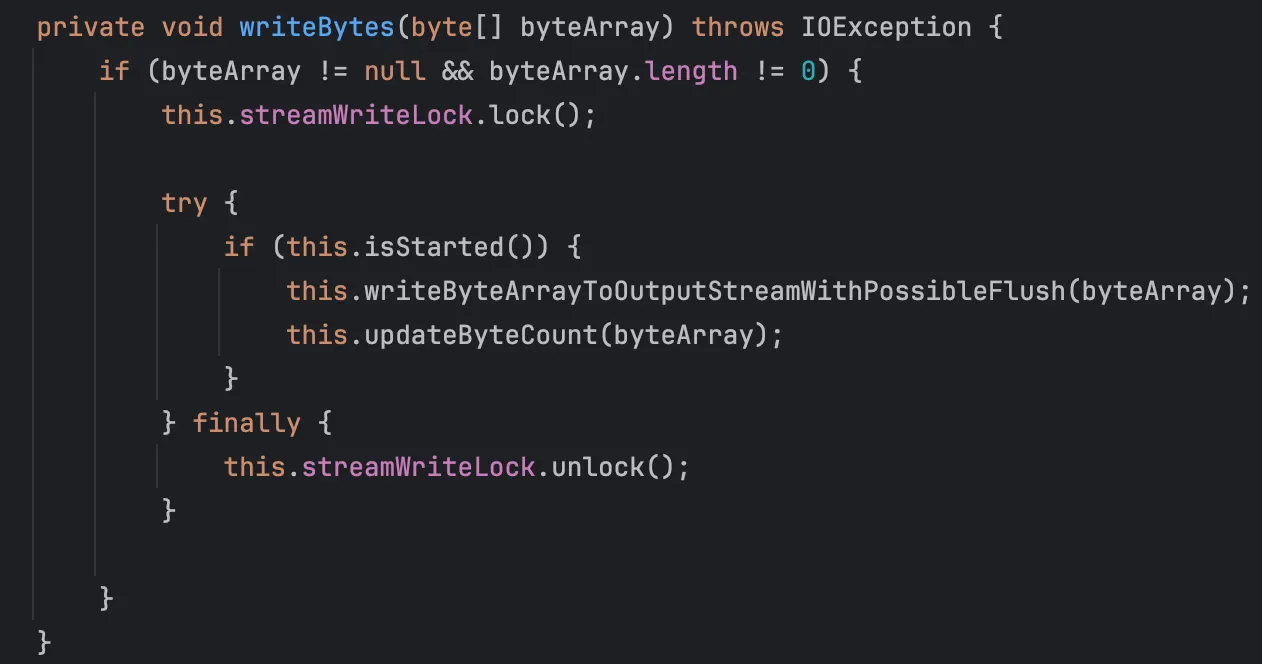
위 사진은 Slf4j의 구현체인 LogBack의 구현된 내용이다. (Slf4j는 인터페이스이다!)
System.out.println은 동기 방식으로 동작하지만, LogBack의 경우 비동기 방식으로 동작하여 더욱 효율적인 것은 사실이나, 실제로 락을 잡으며 버퍼에 쓰는 과정이 포함되어 있어 어느 정도의 오버헤드가 있을 것이라 생각하였다.
또한, 세션 id를 읽어오는 과정에서도 객체에 접근하는 것이기 때문에 조금의 시간이 들 것이라 생각하였다.
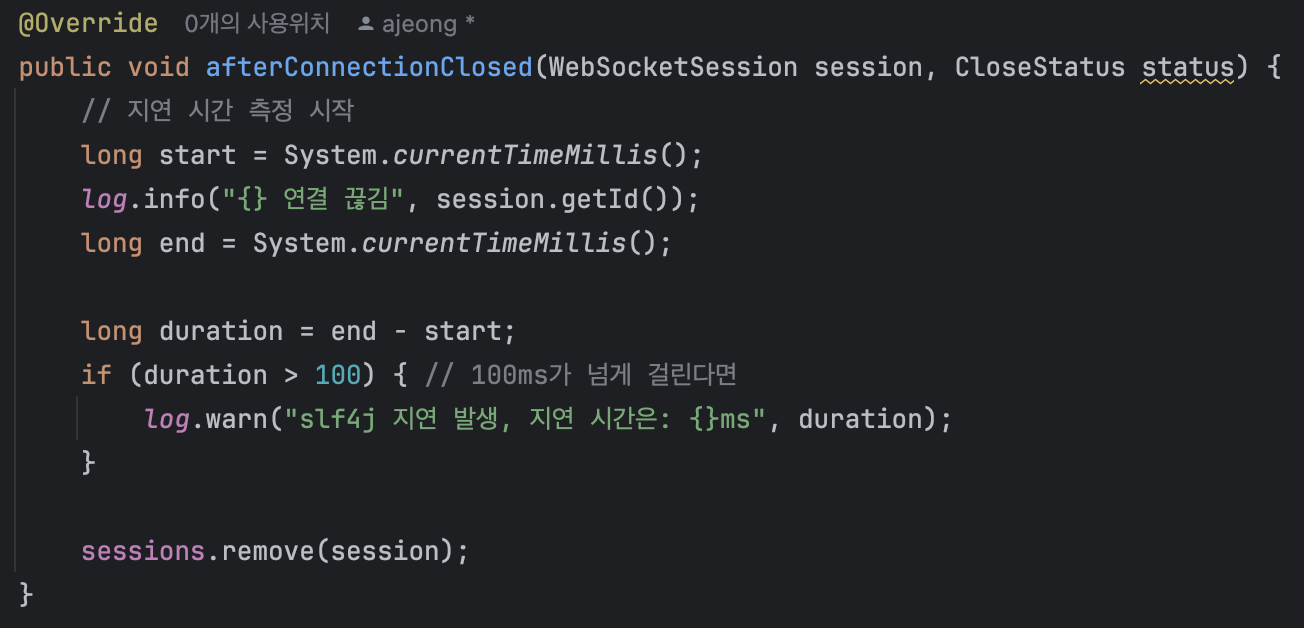
따라서 다음과 같이 로그를 찍는 시간을 두어 로그 지연 시간을 측정하였다.
그러나 첫 로그를 찍은 시간과 마지막 로그 사이에 100ms 이상의 차이를 보이는 로그는 없었다.
따라서 로그는 300ms에 다다르는 지연이 발생하는 것은 직접적인 원인이 아니라고 판단하게 되었다.
✨ 가설 8: TLAB 추가 할당으로 인한 지연이 발생할 것이다. (거짓)
지금까지의 상황 종합 시 GC는 그대로이며, 객체 생명 주기가 길어져 Eden Space -> Survivor Space로의 이동이 많아졌다.
여기서 TLAB이란 Thread-Local Allocation Buffer의 약자로, 각 스레드별 메모리를 할당할 공간을 정해둔 것이다.
TLAB이 가득 차게 되면 전역 락을 잡고, Eden 영역에서 추가적으로 할당을 받아야 한다.
Poller가 하나일 때는 스레드가 TLAB을 사용하고, 다시 할당하는 과정이 천천히 발생하였는데, 두 개로 늘어나며 TLAB 추가 요청이 동시다발적으로 짧은 기간 내 몰리며 Race Condition 상태가 되었다고 생각하였다.
특히, 메모리의 전체적인 사용량은 비슷한데 단기적으로 사용량이 들쑥날쑥하다는 점에 의해 가설에 힘을 싣게 되었다.
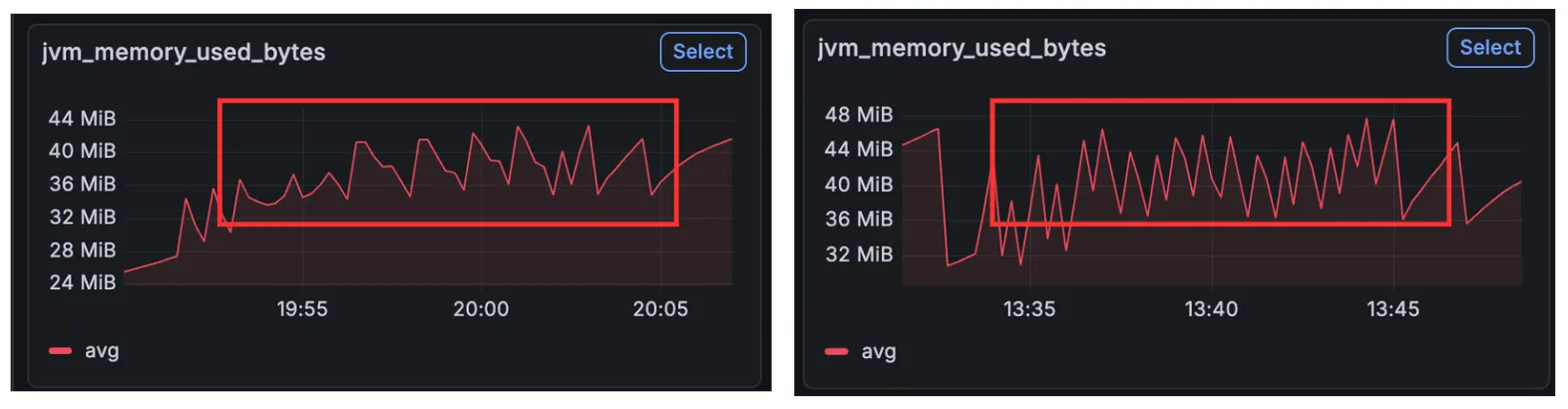
그런데 조금만 생각해 보면 이런 의문이 들 수 있을 것이다.
그렇다면 Eden 영역이 급격하게 뛰었나?
모니터링 지표에 따르면 아니다.
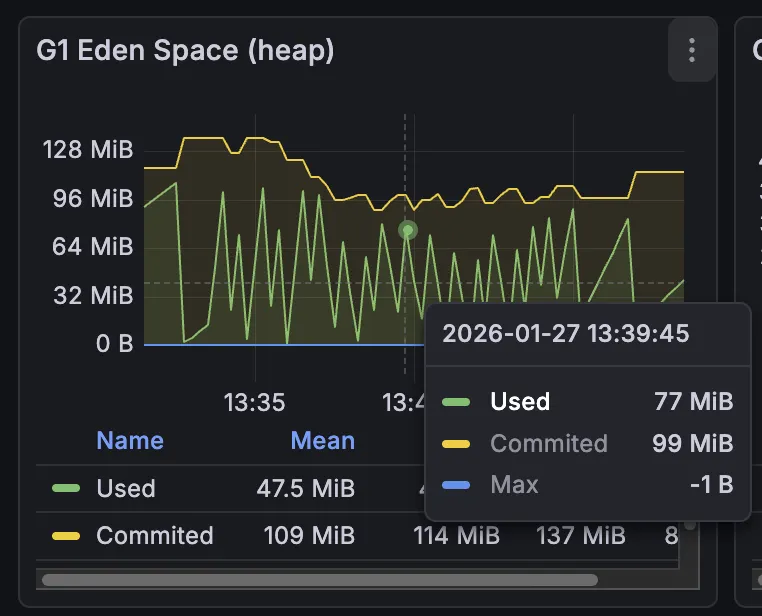
톱니바퀴 모형으로 들쭉날쭉한 것은 보이지만, 훅 튀는 시간대에 Eden Space는 오히려 다른 시기와 다를 바가 없었다.
이를 더 확실하게 증명하기 위해, TLAB의 크기를 각각 1k, 2M으로 바꾸어 테스트를 수행했다.
만약 1K에서는 더 많이 튀고, 2M에서는 덜 튄다면 해당 가설이 참일 확률이 올라간다고 생각하였다.
하지만 1K와 2M의 테스트 결과는 큰 차이가 없었다.
Eden 영역이 급증하지 않은 이유를 설명하지 못하였으며, 테스트 결과 또한 상황과 일치하지 않았으므로 해당 가설 또한 거짓임을 알 수 있다.
✨ 가설 9: 애플리케이션 계층에서의 락 경합으로 인해 지연이 발생하는 것이다. (거짓)
대략적으로 상황을 보자면 다음과 같다.
wakeup()을 받고 깨어난 Poller는 Key 제거, 캐시 삭제, 소켓 close() 등의 일을 처리한다.
이때 모두 락/동기화를 활용하게 된다. 따라서 락 경합에 의해 지연이 발생한다고 생각하였다.
이를 증명하기 위해, Poller를 3개/4개로 늘려 테스트를 진행해 보았다.
이 가설이 맞다면, Poller의 개수와 정비례로 지연 시간이 늘어날 것이다. 락 경합이 심해질 것이라 생각했기 때문이다.
그러나 Poller가 3개/4개일 때 여전히 Max 값이 300ms 근처에서 튀고 있는 것을 확인할 수 있었다.
이 뿐만 아니라, CPU 사용량을 확인했을 때 (process_cpu_usage / system_cpu_usage로 확인) Poller가 한 개였을 때에 비해 오히려 줄어드는 결과를 확인할 수 있었다.
process_cpu_usage: JVM 내에서 사용하는 CPU 사용량system_cpu_usgae: 전체 CPU 사용량
process_cpu_usage / system_cpu_usage를 통해 둘 사이의 간극 비율을 확인할 수 있다. 이것이 크다면 system이 큰데 process가 상대적으로 낮다는 소리이므로 OS 커널에 경합이 생겼다고 예측할 수 있을 것이다.
만약 락 경합이 진짜였다면 다음과 같은 두 가지 상황 중 하나였을 것이다.
- 스핀락 -> CPU 사용량이 올라간다.
- context-switching -> CPU 사용량이 줄어들 것이다.
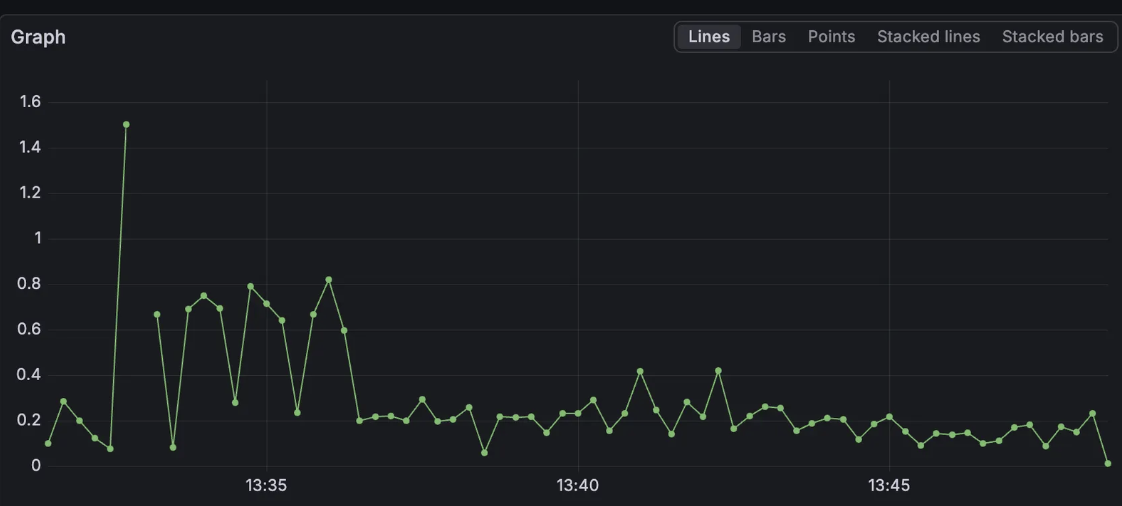
하지만 스핀락이라기에는 CPU 사용량이 올라가지 않았으므로 거짓이다.
context switching 또한 거짓임을 알 수 있는데, 이것이 사실이 되기 위해서는 system cpu와 process cpu 사이의 간극이 올라가야 하기 때문이다.
-> 시스템은 일하는데 프로세스는 놀기 때문이다.
따라서 해당 가설 또한 거짓임을 알 수 있었다.
위 가설들로 보았을 때, 애플리케이션 내부에서 발생하는 문제는 아닌 것 같았다. 왜냐하면 CPU 사용량이 변화하지도 않았으며, GC, 버퍼 등의 주요 지표들에도 유의미한 결과를 찾지 못했기 때문이다.
따라서, 네트워크, OS 등 애플리케이션이 아닌 계층에 초점을 두고자 했다.
✨ 가설 10: 4-way handshake 과정 중 지연이 발생했을 것이다. (참)
💡 4-way handshake 과정
기존보다 더 빠르게 생성이 되며, 빠르게 close()를 호출하고 있는 것을 확인했다. 이에 의해 네트워크 패킷이 전보다 더 많이 이동하므로 이 과정에서 지연이 발생했을 것이라 예측했다.
실제로 간단하게 4-way handshake 과정을 살펴보면 다음과 같다.
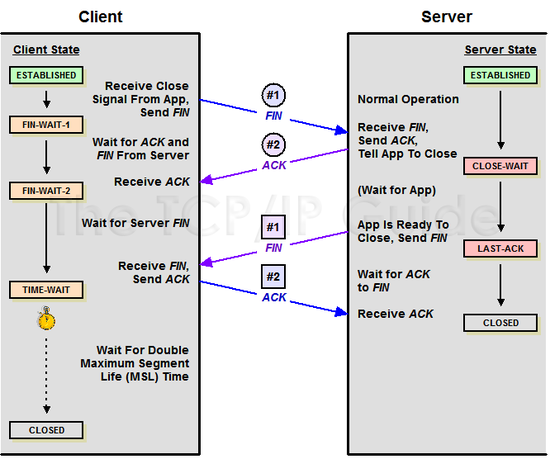 [사진 출처]
[사진 출처]
- 클라이언트 -> 서버: 연결 종료(FIN) 플래그 전송
- FIN 플래그를 받은 서버는 ACK를 보내고, 자신의 통신이 끝날 때까지 기다린다. 이때 버퍼에 쓰기 작업이 남았다면 쓰는 과정을 거친다.
- 서버가 연결을 종료할 준비가 되면 서버 -> 클라이언트로 FIN 플래그를 전송한다.
- 클라이언트 -> 서버로 ACK 메시지를 보낸다.
3-Way handshake는 TCP의 연결을 초기화 할 때 사용한다면, 4-Way handshake는 세션을 종료하기 위해 수행되는 절차이다.
원래 애플리케이션이 write()를 호출해서 곧장 데이터가 이동하는 것이 아니다. 오버헤드를 줄이기 위해 버퍼를 이용하는데, 이때 우선적으로 커널의 메모리 공간인 송신 버퍼에 복사만 하게 되는 것이다.
이후 커널이 네트워크 상황에 맞춰 이 버퍼에 쌓인 데이터를 조금씩 패킷으로 옮기게 된다.
여기서 송신 버퍼(Send Buffer)란 소켓 하나당 할당된 커널 내 메모리 공간으로, 애플리케이션에서 write()를 호출한 데이터가 임시로 머무는 공간을 말한다.
서버는 데이터 유실을 막기 위해 클라이언트 측에서 데이터를 잘 받았다는 ACK 응답이 오기 전까지는 송신 버퍼를 비우지 않고 대기한다.
이 과정에서 클라이언트에서 사용되고 있는 DelayedACKs 옵션에 의해 ACK 응답이 지연되어서 한 번에 오고, 서버는 응답을 늦게 받아 송신 버퍼를 비우지 못하고 기다리는 것에 의해 응답 시간 지연 문제가 발생한다고 판단하였다.
💡 테스트 수행 - SO_LINGER
이를 확실시하기 위해, SO_LINGER 옵션을 켜고 테스트를 수행했다.
여기서 SO_LINGER 옵션은 C에서 제공되는 TCP 소켓 옵션으로, 톰캣 설정 시에는 soLingerOn으로 나타나게 된다.
원래는 클라이언트의 ACK 응답을 받은 후 끝냈다면, 해당 옵션을 켜게 되면 클라이언트의 ACK 응답을 받지 않고 곧장 종료해버린다.
따라서 수행 결과에서 max latency가 눈에 띄게 줄어든다면 송신 버퍼에서 기다리는 과정에서 지연이 발생했다는 뜻이므로 가설이 참임을 확신할 수 있는 것이다.
💡 테스트 결과
다음은 테스트 결과이다.
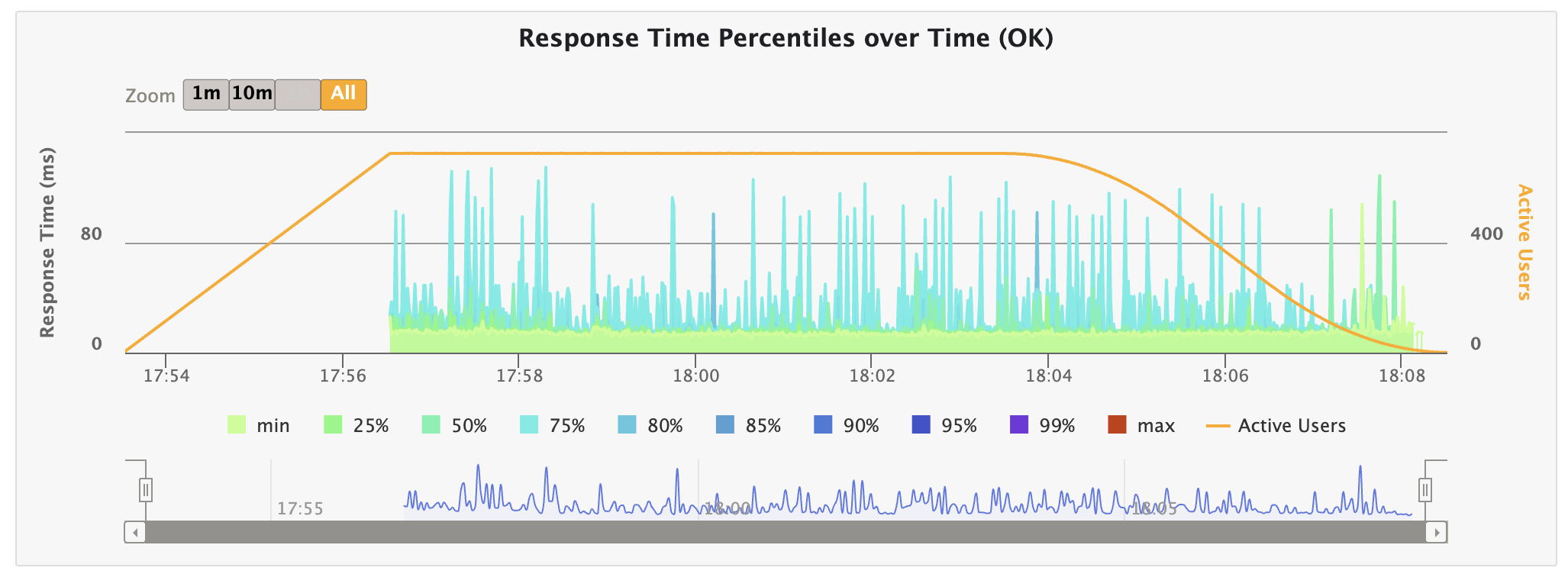
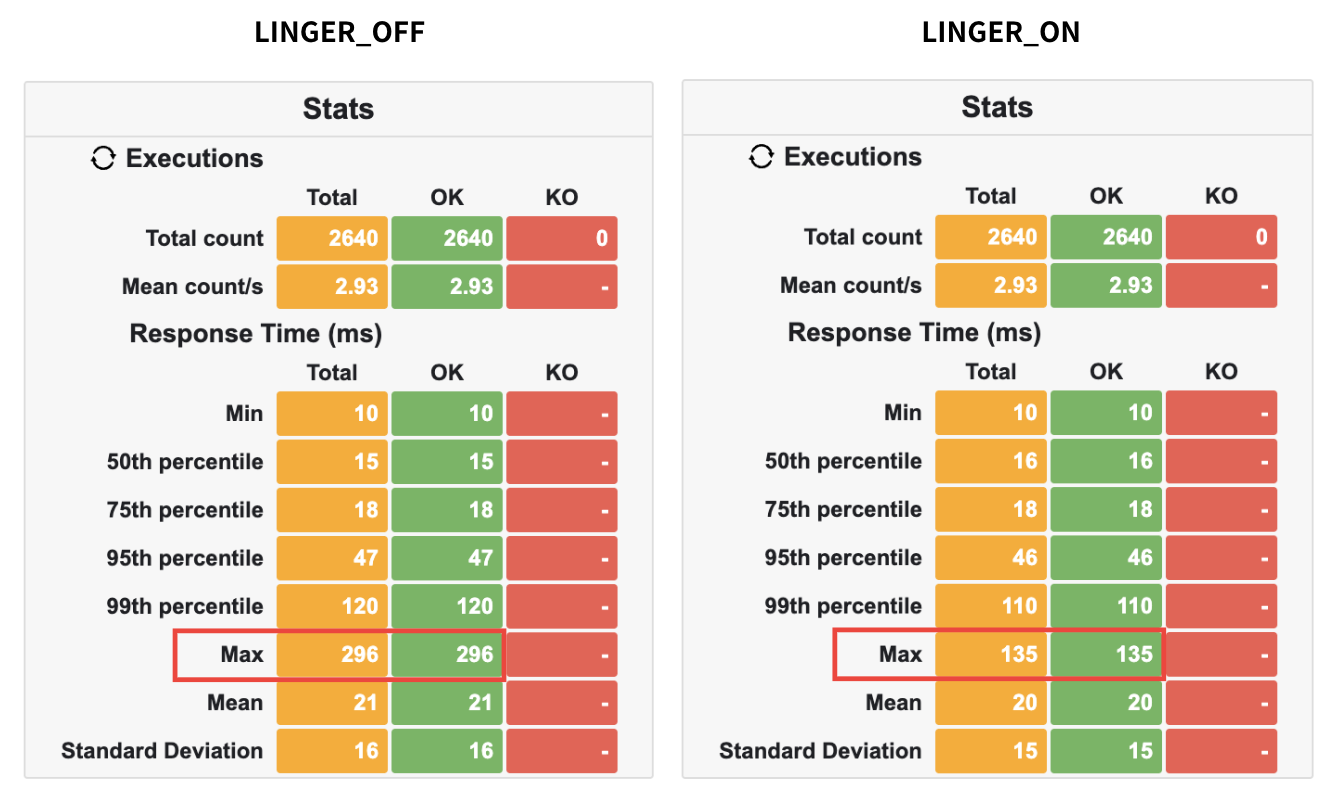
Max Latency 수치가 잡힌 것을 알 수 있다.
실제로 netstat로 확인 결과, DelayedACKs이 317번 일어났음을 알 수 있다.
추가로 TCPTimeouts는 저번 글(Multi-Poller 도입)에서와 마찬가지로 변화하지 않았다. 보낸 패킷에 대한 지연이 없었다는 의미이다.
더욱 정확한 비교를 위해 Poller가 하나일 때, netstat를 확인해보았다. (SO_LINGER 옵션 off)
예상대로 DelayedACKs 변화량이 293 -> 317로 8.2% 증가한 모습을 보인다.
Poller가 두 개로 늘어나며 Delay되는 ACK가 증가하였음을 알 수 있다.
🫧 해결 방법
현재 4-way handshake 과정 중 서버가 버퍼에 데이터를 쓰고 다시 ACK 과정을 받기까지의 지연이 있다는 사실을 알았다.
실제로 SO_LINGER 옵션을 사용해 ACK 응답을 받지 않아도 대기 없이 끝낼 수 있도록 바꾼 결과, Max Latency가 잡힘을 확인할 수 있었다.
그런데 SO_LINGER의 경우 ACK를 받지 않기 때문에 빠르지만 데이터가 유실될 위험이 있다.
그렇다면 SO_LINGER 옵션을 사용하지 않고, 근본적으로 패킷의 수를 천천히 처리하거나 줄일 수 있는 방법이 있는지 살펴보고자 했다.
현재 문제가 되는 부분은 서버가 ACK를 보내고 -> 송신 버퍼에 데이터를 쓰고 -> FIN을 보낸 후, 클라이언트의 ACK를 받는 과정에서의 지연이다.
따라서 송신 버퍼에 데이터를 쓰거나 ACK를 빠르게 받는 방식으로 고치는 것을 생각하였다.
송신 버퍼의 경우 OS 계층이기 때문에 송신 버퍼의 크기를 늘리거나 줄이는 방식으로 수정할 수 있을 것이다.
ACK를 빠르게 받는 방법도 마찬가지로, 클라이언트 쪽의 설정을 변경하면 될 것이다.
그러나 해당 수정 방법은 문제 자체의 본질에 집중하는 것보다는 임시적인 방편을 도입하는 것이라 생각했다. 따라서 본질적으로 어떤 부분에서 딜레이가 발생하는지 파악하고 해당 부분을 고치는 것이 좋을 것 같다는 생각이 들었다.
따라서 어떤 것이 문제를 불러 일으켰는지 다시 파악하고자 했다.
우리가 알고 있는 것은 Poller를 1개에서 2개로 늘리며 DelayedACKs가 293 -> 317로 8.2% 증가하여 딜레이되는 패킷이 늘어났다는 것이다.
Multi-Poller를 도입하면서 전보다 더 빠르게 패킷을 처리할 수 있게 되었고, 이로 인해 수신 버퍼에서 읽어오는 속도가 확실히 증가했음은 알 수 있지만, 빠른 패킷이 한 무더기씩 가면서 DelayedACKs가 늘어난 것이라고 생각한다.
✨ 왜 DelayedACKs가 늘었을까?
그렇다면 왜 DelayedACKs가 늘었을까?
DelayedACKs는 작은 패킷들이 빠른 간격으로 도착할 때 트리거되어 발생한다.
이 말을 현재 상황에 대입해보면, close() 주기가 몰리며 DelayedACKs가 발생할 수 있는 상황을 만들어냈고, (4-way handshake 몰림) 이로 인해 DelayedACKs가 전보다 8.2% 증가한 것이라 해석할 수 있다.
그러면 객체 생명 주기가 길어짐에 의해 close()가 늦어졌으므로 (또는 반대) 객체 생명 주기와 관련해서 어딘가 지연이 발생하는 곳이 있는지를 봐야 할 것이다.
처음에는 단순히 스레드가 부족함을 의심했다.
그러나 실제로 스레드 상태를 확인한 결과, 스레드는 부족하지 않았다.
그렇다면 무엇이 문제일까? 여러 지표들을 확인하면서, 다시 스레드 상태에 주목할 수 있었다.
계속해서 waiting / timed-waiting 상태에 머물러 있는 스레드가 눈에 띈 것이다.
다음 코드를 보자.
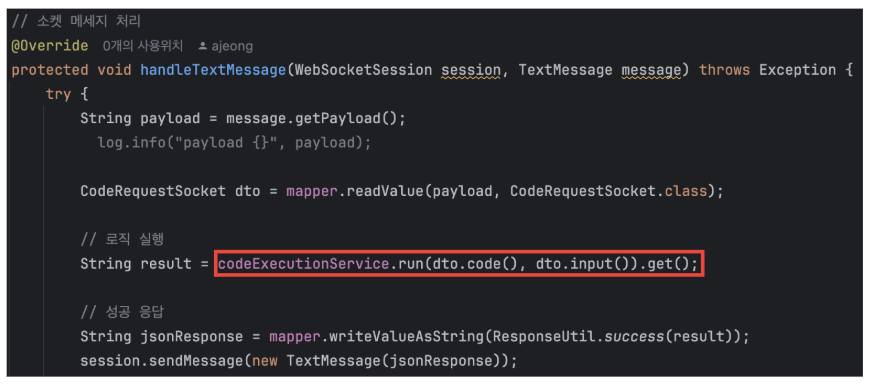
그렇다.. 나는 웹소켓 처리 메서드를 get()으로 Block 해두고 있었던 것이었다.
위 사진처럼 로직 실행 시 get()으로 결과를 받아오고 있는데, 이 과정에서 할당된 톰캣 스레드가 block 되어 결과를 받지 못하고, close() 호출까지 지연이 됨을 의심할 수 있다.
실제로 TextWebSocketHandler의 handleTextMessage() 를 오버라이드한 내 코드는 따로 설정을 건드리지 않았기 때문에 기본적으로 톰캣 스레드로 수행이 된다.
모든 Tomcat 스레드가 block 되어 있기 때문에 handleTextMessage()에서 수행된 결과를 한 번에 보내면서 4-way handshake 과정이 겹쳤고, 이로 인해 DelayedACKs가 늘어났다는 판단을 할 수 있다.
따라서 톰캣 스레드가 직접 실행하지 않고 비동기 처리를 한다면 write() 실행 시간을 조정하여 문제를 해결할 수 있을 것이라 생각하였다.
이를 증명하기 위해 스레드 덤프를 활용해 스레드의 상태를 파악해 보았다.
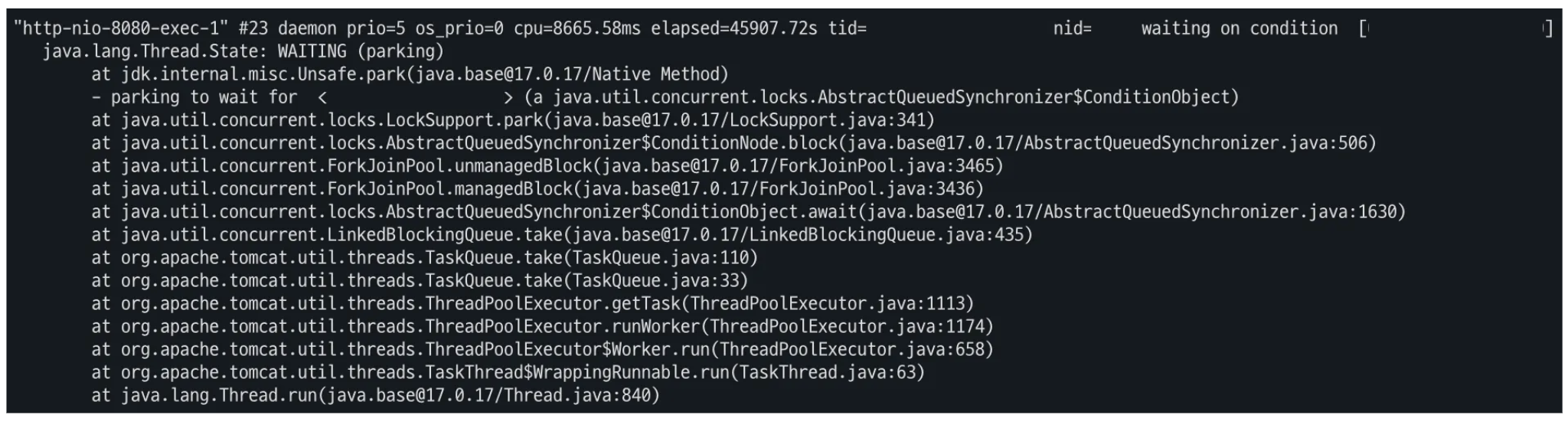
평소는 이렇게 waiting 상태였지만, 가끔 아래 사진처럼 직접 오버라이딩한 handleTextMessage()가 실행됨을 알 수 있다.
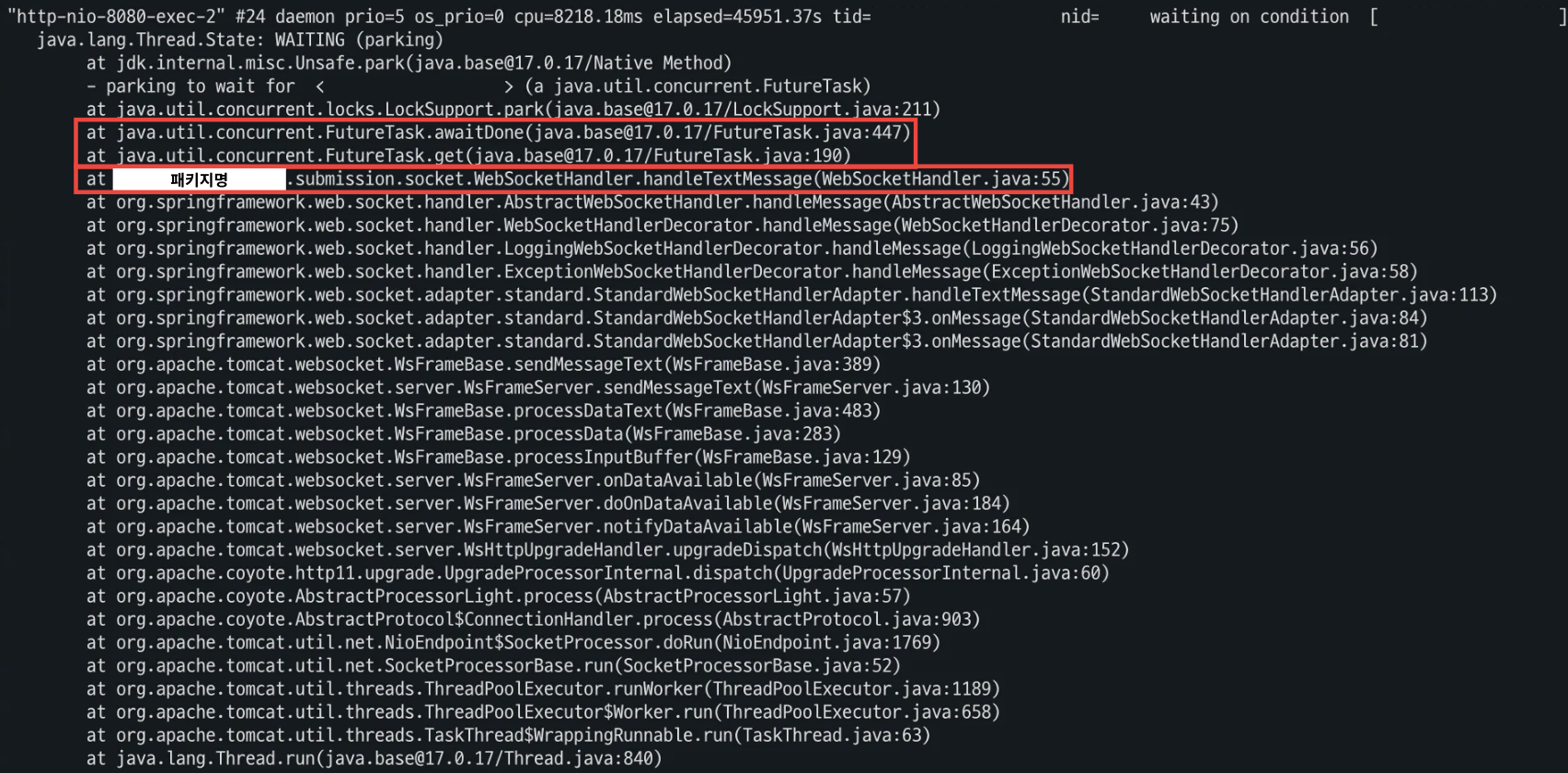

직접 구현한 WebSocketHandler.handleTextMessage()가 실행되고 있음을 파악할 수 있었다.
해당 상태가 드물지만 종종 나타나고 있었는데, 이는 Multi-Poller를 도입하면서 전체적인 성능은 개선되었지만 (대부분의 tomcat thread가 waiting 상태) 간혹 run()에서 일시적으로 block되어 이 과정에서 close()시 튀는 현상이 발견되는 것 같았다.
따라서 비동기 콜백 전환을 통해 톰캣 스레드가 block되어 일시적으로 튀는 현상을 해결하고자 한다.
이를 통해 4-way handshake 과정에서 서버가 FIN을 보낸 이후 다시 ACK를 받기까지의 과정에 드는 지연 시간을 줄이고자 했다.
🫧 해결 (테스트 결과)
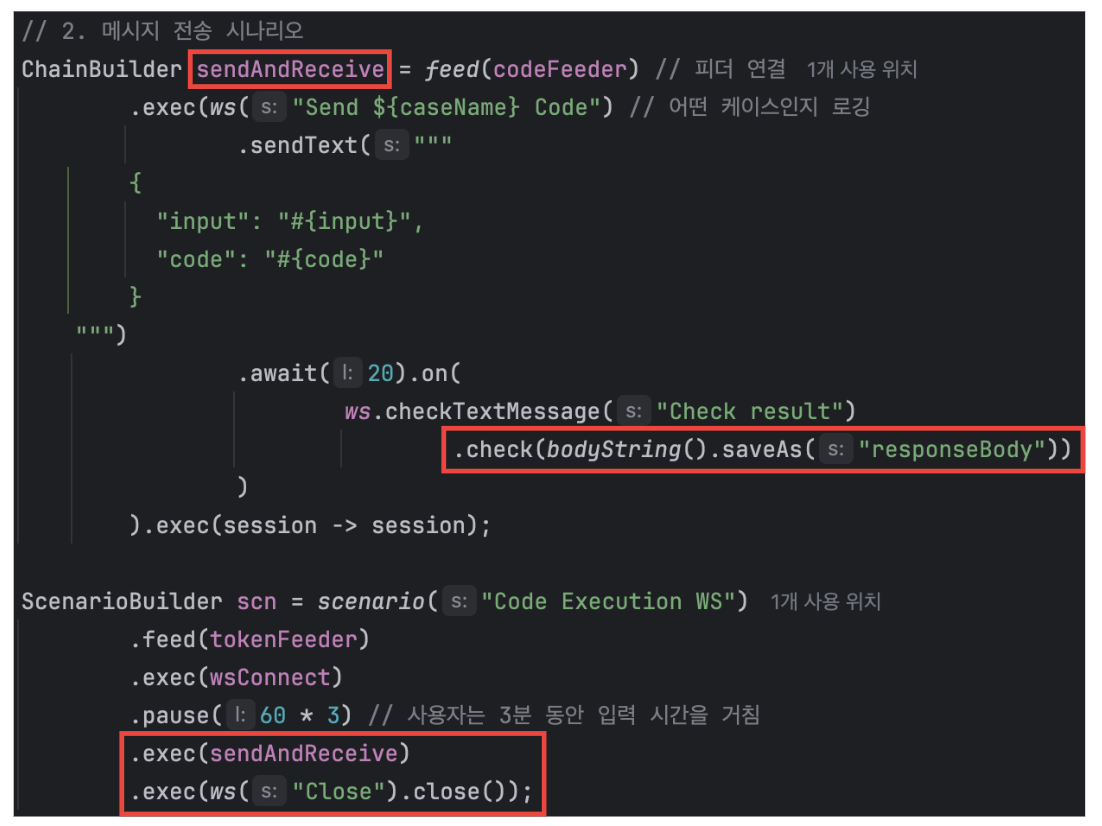
동기적으로 구현되어 있던 handleTextMessage 부분을 비동기 콜백 함수로 교체한 코드이다.
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) {
try {
String payload = message.getPayload();
CodeRequestSocket dto = mapper.readValue(payload, CodeRequestSocket.class);
// 비동기 처리
CompletableFuture.supplyAsync(() -> {
try {
return codeExecutionService.run(dto.code(), dto.input()).get();
} catch (Exception e) {
throw new RuntimeException(e);
}
}).thenAccept(result -> {
// 2. 결과 얻은 후 실행
try {
// 세션이 열려 있다면
if (!session.isOpen()) {
log.error("[ERROR] 세션이 이미 닫혀 있습니다. (SessionID: {})", session.getId());
return;
}
// 응답 보내기
String jsonResponse = mapper.writeValueAsString(ResponseUtil.success(result));
session.sendMessage(new TextMessage(jsonResponse));
} catch (Exception e) {
log.error("결과 반환 후 응답 보내는 과정 중 오류:", e);
}
});
} catch (Exception e) {
log.error("handleTextMessage 시 오류 발생:", e);
}
}
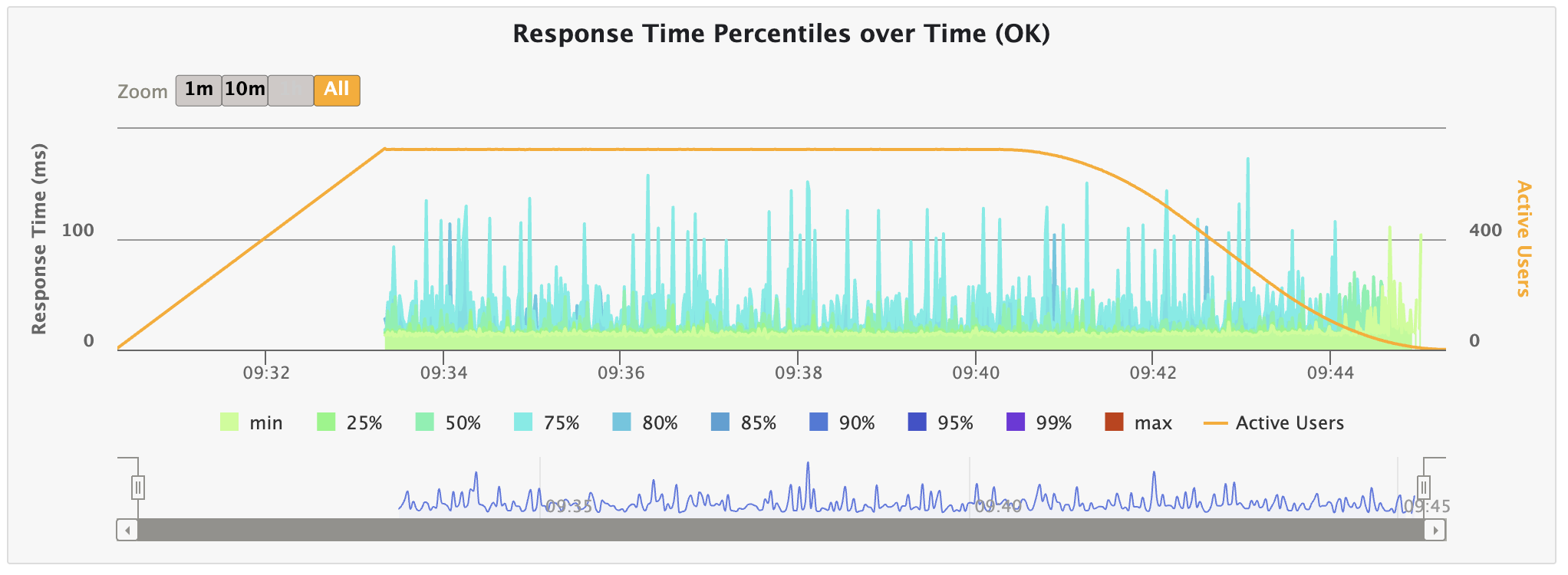
테스트 결과, close() 시 Max Latency가 튀는 현상을 잡을 수 있었다.

지표로 보았을 때, Max Latency가 296ms -> 173ms로, 41.5% 감소하였음을 증명할 수 있었다.
또한, netStat으로 지표를 다시 확인해 보았다. 이는 각각 테스트한 결과로, 전체적인 네트워크 주요 지표 변화량을 계산하여 작성한 내용이다.
| 지표 | Poller-1 | Poller-2 | Poller-2/비동기 |
|---|---|---|---|
| TCPAbortOnData | 104 | 81 | 53 |
| DelayedACKs | 293 | 317 | 203 |
| TCPTimeouts | 0 | 0 | 0 |
이를 토대로, 다음 두 가지를 알 수 있다.
- 송신 버퍼가 비워지지 않은 상태에서 close() 호출 줄어듦. (TCPAbortOnData)
- DelayedACKs는 비동기 처리했을 때 약 36% 감소한 것을 확인할 수 있음
- Timeout은 발생하지 않음
실제로 처리량은 약 80,000 개의 연결이었음을 감안했을 때, 연결의 0.07%가 송신 버퍼가 비워지지 않은 상태에서 close 처리됨을 알 수 있다.
그러나 이 부분은 Gatling 테스트 환경 특성상 close()의 잦은 호출로 인해 발생하는 일이라고 생각하였으므로, 해당 부분은 우선적으로 수정 사항에서 배제하기로 했다.
✨ close() 시 의도적 지연 주기
그런데 문득 궁금증이 들었다. 그렇다면 close() 시에 지연을 준다면 TCPAbortOnData의 값이 줄어들까?
현재는 아래와 같은 상태로, 바로 close()를 호출해 문제가 발생한다고 판단하였기 때문이다.
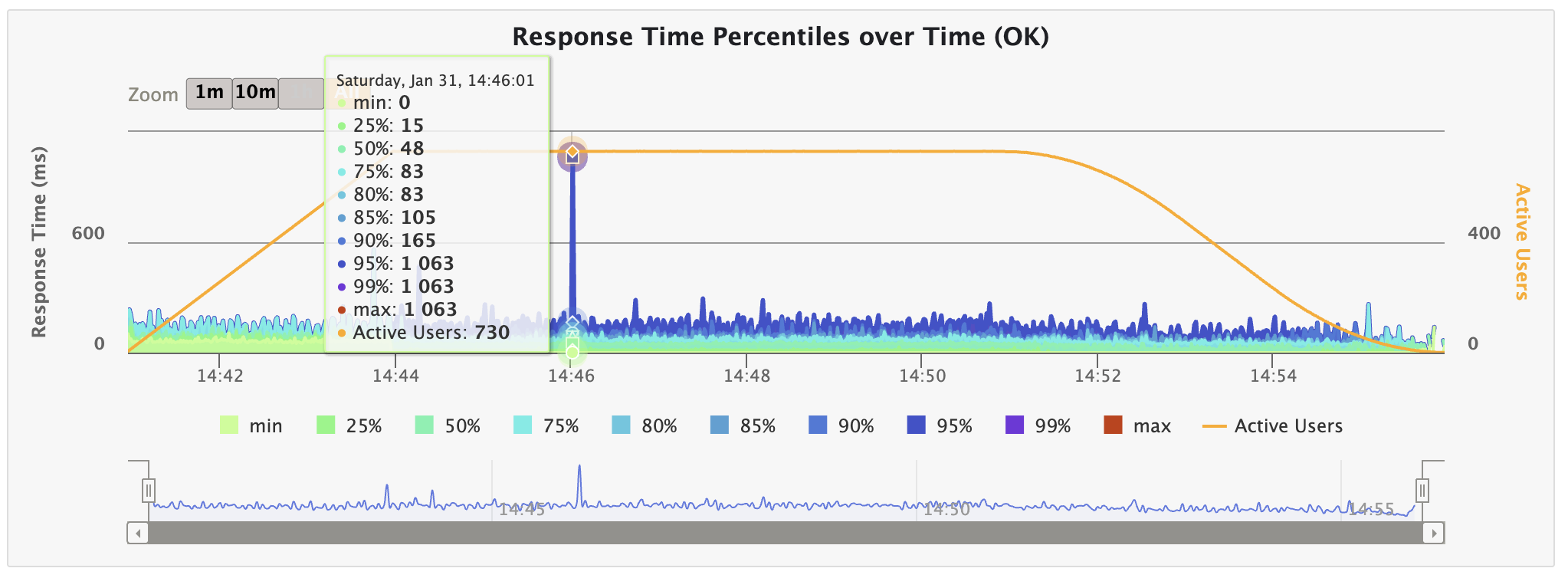
1초 대기 후 close()를 호출해보았는데, 실제로 53건이었던 TCPAbortOnData가 93건으로 늘어났음을 알 수 있다.
그러나 1초 대기 후 close()에 의해 동시 접속 사용자 수가 전보다 3명 정도가 늘었으며, Poller 1개일 때 보였던 스파이크 현상이 그대로 다시 나타남을 확인할 수 있었다.
이는 현재 상황이 과부하 상태에 놓여있음을 알 수 있다.
사실 헷갈려서 1초 대기가 아닌 1분 대기로 바꿨었는데, 이때 500 에러가… 났다.
이는 추후 해결 해야 할 문제로 남겨두겠다. (다음 글에서 다룰 예정!)
그래서 close() 전 대기 시간을 0.1초로 바꾸어 테스트를 진행했는데, 다음과 같은 결과를 얻을 수 있었다.
| 지표 | 비동기 | 1초 지연 | 0.1초 지연 |
|---|---|---|---|
| TCPAbortOnData | 53 | 93 | 98 |
| DelayedACKs | 203 | 190 | 189 |
| TCPTimeouts | 0 | 0 | 0 |
DelayedACKs는 미세하게 줄어들었지만 TCPAbortOnData의 값이 지연으로 인해 약 두 배 가량 증가했음을 알 수 있다.
클라이언트 측에서 close() 호출 전 임의로 지연을 줌으로써 서버가 송신 버퍼를 비울 시간을 주었다고 생각했는데, 그것이 아닌 것 같았다.
DelayedACKs의 차이는 별로 없지만, TCPAbortOnData가 두 배 가량 발생하는 것으로 보아, 서버의 안정성을 위해 지연을 주지 않고 문제를 해결하는 것이 더 좋아보였다.
또한 결과로 보건대, TCPAbortOnData는 다른 이유로 발생하는 것이 아닐까 하는 의심도 들었다.
그러나 우선은 글이 길어질 것 같으므로 이 문제는 다음에 찾아서 정리해야겠다.
🫧 결론
close() 과정에서 Max Latency가 튀는 이유는 4-way handshake 과정에서 지연이 발생했기 때문이었다. 이는 TCP의 동기적 메커니즘에 의해서 발생하는 일로, 서버가 FIN을 보내고 클라이언트의 ACK 응답을 기다리는 과정에서 발생한 일이었다.
문제 상황은 다음 두 가지였다.
- DelayedACKs로 인해 클라이언트에서 보내는 ACK 요청이 지연된다.
- 톰캣 스레드가 Future.get()으로 Block되어 있어 write() 요청이 한 번에 몰린다.
이를 SO_LINGER를 활용해 ACK 요청을 기다리지 않고 바로 받을 수 있게 테스트하였는데, Max Latency가 잡히며 문제가 해결됨을 알 수 있었다.
그러나 이는 가설 검증을 위한 임시 해결책임을 깨닫고, handleTextMessage 함수를 비동기 콜백 함수로 전환하여 Max Latency를 41.5% 감소시킬 수 있었다.
하지만 여전히 연결이 중간에 끊기는 데이터가 53건이 존재한다는 문제가 있었다. 따라서 close() 호출 전 지연 시간을 두어 테스트를 해 보았으나, TCPAbortOnData 값이 증가하여 지연 시간은 넣지 않기로 했다.
이번 문제는 애플리케이션 계층에서의 문제라기보다는 네트워크에서의 문제였기 때문에 모니터링으로 관측이 어려웠다.
게다가 핀포인트 또한 너무 무거워서 제대로 사용을 못 했었고… 찾는데 정말정말 힘들었다.
그러나 이 과정을 거치면서 네트워크에서 어떻게 송수신하는지 알게 되었으며, 튀는 문제를 잡을 수 있어서 정말 뿌듯했다.
앞으로 고칠 점은 수도 없이 많지만.. 이렇게 가설을 정의하고 실패하며 문제 범위를 좁혀 나가면 나중에는 안 보고도 찾을 수 있는 날이 오지 않을까(?) 하는 기대가 된다.
🫧 아쉬운 점
그러나 여전히 아쉬운 점은 존재한다.
테스트 결과를 다시 확인하자.
응답 시간이 전체적으로 (아주 살짝) 올라갔지만, 표준편차 또한 16 -> 18로 증가했음을 알 수 있었다.
그리고 마지막!! 굉장히 심각한 문제.. 500 에러를 수정하도록 해야겠다.
앞으로 이런 문제들을 다시 정의하고 해결하는 과정을 거치며 더욱 안정적인 서버를 구축하고 싶다는 생각이 들었다.
🫧 참고 자료
- 4way handshake
- 소켓 프로그래밍 SO_KEEPALIVE 옵션 사용법/SO_LINGER 옵션 사용법
- 오픈소스 분석 - Tomcat 소켓 I/O 동작 방식 파헤쳐보기(BIO, NIO Connector)
- [네트워크] 3way / 4way Handshake란?
- What Is a TLAB or Thread-Local Allocation Buffer in Java?
- 백엔드 성능에 영향을 미치는 네트워킹 개념, 성능에 대한 지연된 승인의 효과
- 네트워크 엔지니어링 (Network Engineering) 마스터하기! Section 7 백엔드 성능에 영향을 미치는 네트워크 개념